String类详解
热衷学习,热衷生活!😄
沉淀、分享、成长,让自己和他人都能有所收获!😄
一 String描述
1 | public final class String implements java.io.Serializable, Comparable<String>, CharSequence { |
String是一个用final声明的常量类,不能被任何类继承,底层是由char[]数组实现,这个数组也是final,一旦String对象被创建,包含这个对象中的字符序序列是不可被改变的,改类后续的所有方法都是不能改变该对象的,直至该对象被销毁(该类的有些方法看似改变了字符串比如substring、replace等,其实都是内部创建了一个新的字符串)。实现了Serializable系列化接口,实现了Comparable接口,用于比较两个字符串的大小(按顺序比较单个字符的ASCII码),最后实现CharSequence表示是一个有序字符的集合。
二 创建方法
String最常用的创建方法就是String str = "str",实际上String底层是由一个char[]数组实现的,所以也可以String str = new String(new char[]{'s', 't', 'r'}),还可以由下面方法创建:
1 | String str01 = "str"; |
声明一个字符串对象的方法一般有两种:
通过“字面量”的形式直接赋值
1
String str = "str";
通过new关键字调用构造方法创建对象
1
String str = new String("str");
通过”+”运算符创建对象
1
2String str01 = "s" + "str";
String str02 = str01 + "str";
那么这两种声明方式有什么不一样呢?首先我们要介绍一个常量池,Java在运行时会维护一个String池(String Pool),也叫字符串缓存区。String池用来存放运行时中产生的各种字符串。并且字符串的内容不重复。
在JDK1.7之前,常量池是存放在方法区的,用来储存编译期生成的字符串引用。而在JDK1.7之后,常量池存放在堆中了。
- 字面量创建字符串或者纯字符串(常量)拼接字符串时会现在字符串池中查找,看是否有相等的对象,有的话则直接使用String池中的引用;没有的话就在字符串池中创建该对象,避免重复创建对象。
- new关键字创建时,直接在堆中创建一个新对象,变量所引用的都是这个新对象的地址,但是如果创建的字符串内容在常量池存在了,那么会由堆再指向常量池的字符串;如果不存在,那么通过new关键字创建的字符串对象是不会在常量池中维护的。
- 使用包含变量表达式来创建String对象时,不仅检查维护String池,还会在堆区创建这个对象,最后指向堆内存中的对象。
举个例子:
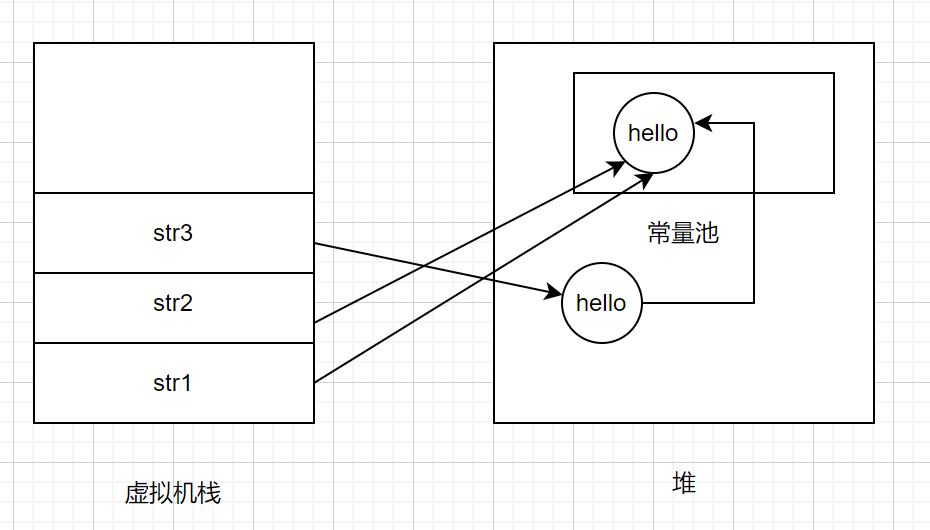
1 | String str1 = "hello"; |
对于上面情况,首先String str1 = "hello",会先在常量池检查是否有hello存在,发现是不存在的,则在常量池中创建hello对象,并将常量池中的引用赋值给str1;紧接着String str2 = "hello",在常量池中检测到有hello,所以讲常量池中的引用赋值给str2,所以str1 == str2是true;紧接着String str3 = new String("hello"),常量池中有了hello,所以不用在常量池中创建,然后在堆中创建该对象并将对象的引用赋值给str3,再将该对象指向常量池。如下图所示:
使用包含变量表达式创建对象:
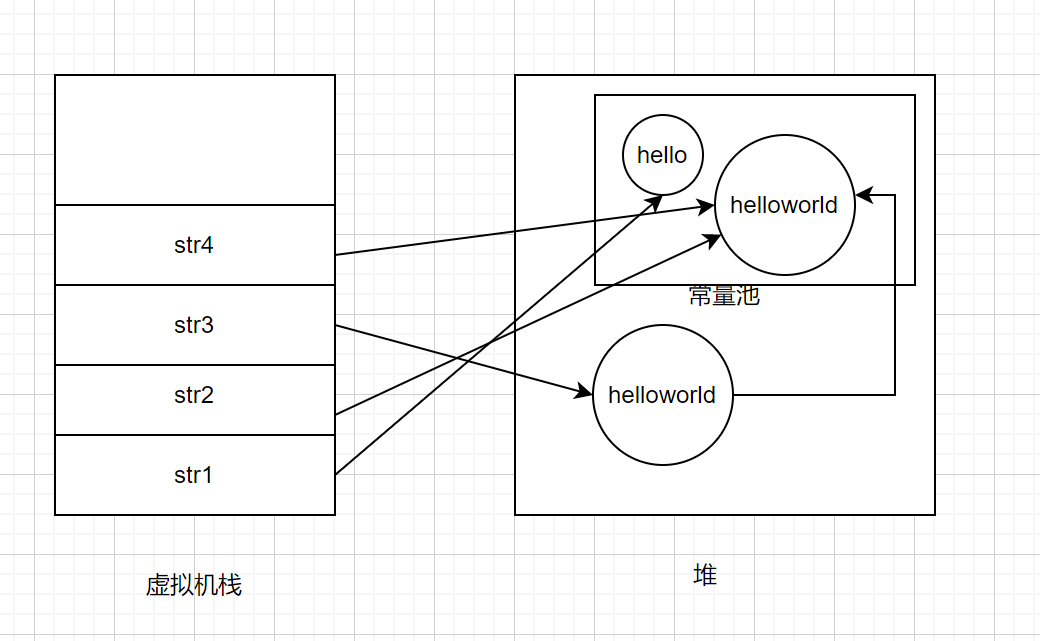
1 | String str1 = "hello"; |
str3由于含有变量str1,编译器不能确定是常量,会在堆中创建一个String对象。而str4是两个常量相加,编译器确定会常量,直接饮用常量池中的对象。如下图所示:
三 不可变(final)
String最重要的特性就是不可变,这种不可变性是通过底层private final char value[]属性,以及没有任务修改char[]的方法实现。举个经典的例子,不考虑其他情况,下面初始化String分别创建了几个对象呢?
1 | String str01 = "abc"; |
- str01创建一个对象,引用指向abc
- str02创建一个对象,引用指向abcdef,这是因为JVM编译期的优化两个字符串会拼接起来。
- str03会创建三个对象,str01对象,+的时候会创建StringBuilder对象进行append操作,append完成toString创建对象。
但是真的不可以变吗?
我们知道String底层是由char[] value实现,value被final修饰,只能保证引用不被改变,value是可以被改变的,即使被private声明,我们还是可以通过反射来改变value值的。
1 | String str = "str"; |
通过前后的两次打印的结果,我们可以看到String被改变了,但是在代码里面几乎不会用反射去改变String的值,所以我们认为String类型是不可以变的。
那么,String类为什么要设计成不可变呢?我们可以从安全和性能两个方面来考虑:
- 安全:
- 引发安全问题,譬如数据库名称、密码都是字符串的的形式传入获取数据库连接,或者在socket编程中主机名和端口都是以字符串的形式传入。因为字符串是不可以变的,所以它的值是不可变的,否则黑客们可以钻到空子,改变字符串指向的对象的值,搞成安全漏洞。
- 保证线程安全,在并发环境中多个线程同时读写资源时,会引起线程不安全,由于String是不可以变的,不会引起线程问题。
- HashCode,当String被创建的时候,HashCode的值也会被缓存,HashCode的值与value有关,如果String改变,那么HashCode也会随之改变,针对Map、Set等容器的键值需要保证唯一性和一致性,String不可以变保证了这个特性。
- 性能
- 当字符串不可变时,字符串常量池才有意义。字符串常量池的出现,可以减少创建相同字符的字符串,让不同的引用指向同一个字符串,为运行时节约了很多堆内存。若字符串改变,字符串常量池则失去意义,基于常量池的
String.intern()方法也会失效,每次创建新的String将在堆内存创建新的空间,占用更多更多的内存。
- 当字符串不可变时,字符串常量池才有意义。字符串常量池的出现,可以减少创建相同字符的字符串,让不同的引用指向同一个字符串,为运行时节约了很多堆内存。若字符串改变,字符串常量池则失去意义,基于常量池的
四 intern()方法
1 | /** |
从源码中可以看出intern()是一个native方法,但是注释写的非常清楚了。”如果常量池中存在当前字符串,则直接返回当前字符串,如果常量池中没有该字符串,会将此字符串放入常量池中后,再返回”。
native是一个本地方法,底层通过JNI调用C++方法,核心方法如下:
\openjdk8\jdk\src\share\native\java\lang\String.c
1 | Java_java_lang_String_intern(JNIEnv *env, jobject this) |
它的大体实现就是:Java通过JNI调用C++实现的StringTable.intern方法,StringTable.intern方法跟Java中的HashMap实现差不多,只是不能扩容,默认大小1009。要注意的是String的String Pool是一个固定的大小HashTable,默认值大小是1009,如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表很长,而链表长了就会直接造成调用String.intern性能下降。在JDK6中StringTable是固定的,JDK7可以通过参数-XX:StringTableSize=99991指定。
JDK6和JDK7下intern的区别
我们都做过类似String abc = new String("abc")这个语句创建了几个对象的题目。这种题目主要是为了考察我们对字符串对象的常量池掌握与否。上面的语句创建了2个对象,一个对象是”abc”字符串储存在常量池,另一个是在Java堆中的String对象。
1 | String s = new String("1"); |
打印结果是
- JDK6
falsefalse - JDK7
falsetrue
JDK6中的解释
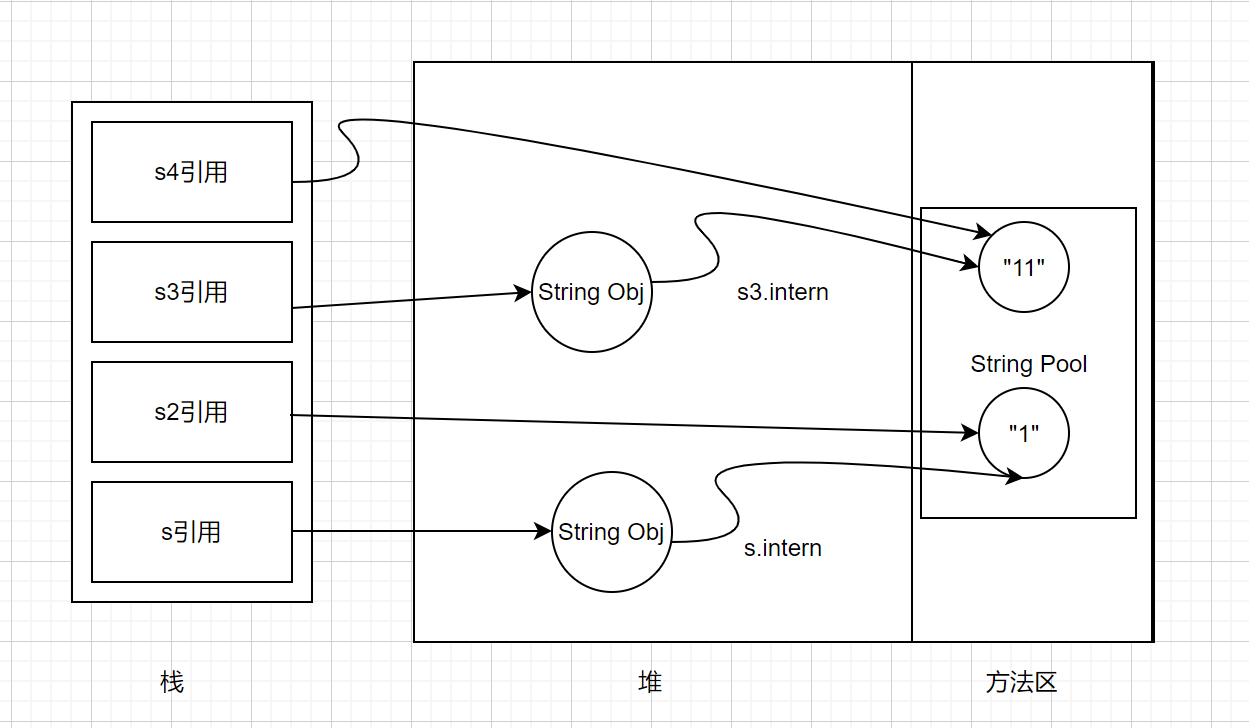
注:图中红色线条代表 string 对象的内容指向。 黑色线条代表地址指向。
在JDK6中都是false,因为JDK6中常量池是在方法区中,方法(Perm)区和堆(Heap)是完全分开的。上面代码中用引号直接创建的对象会直接在常量池中,而new出来的String对象是在堆中的,所以拿一个方法(Perm)区的对象地址和堆(Heap)中的对象地址做比较是肯定不相同的。
JDK7中的解释
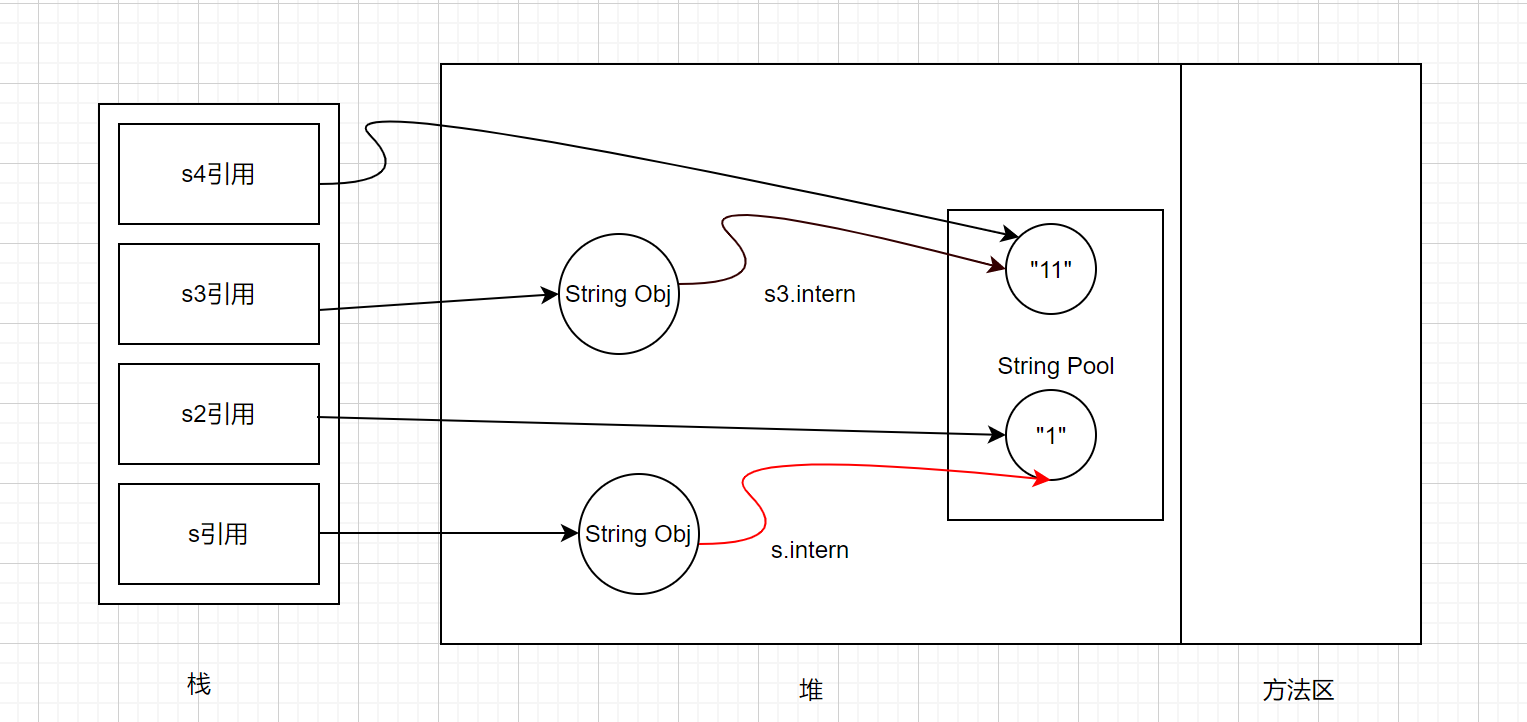
在JDK7中,打印结果是false true,字符串常量池是在堆(Heap)中的,解释如下:
- 在第一段代码
String s = new String("1");生成两个对象,一个是常量池中的“1”和JAVA堆(Heap)中的字符串对象。s.intern;这一句是s对象去常量池中寻址后发现有”1”已经才常量池中了。 - 接下来
String s2 = "1";这句代码是生成s2的引用对象指向常量池中的”1”对象,s1和s2的引用地址明显不同,所以是false。 - 再看
String s3 = new String("1") + new String("1");这句代码最终生成2个对象,是字符串常量池中的”1”和堆(Heap)中s3引用的对象,中间还有两个匿名对象先不讨论。此时s3引用对象的内容是”11”,而且”11”在常量池中是不存在的。 - 接下来
s3.intern();,将s3中的”11”字符串存入String常量池,因为此时常量池中没有”11”,所以在常量池中生成”11”对象,关键JDK中常量池不存在方法区了,而是存在堆中,常量池中不需要在储存一份对象了,可以直接存储堆中的引用,也就是说引用地址就是s3的引用地址。 - 最后
String s4 = "11";是声明创建字符串,所以是直接去常量池创建,此时常量池存在”11”对象了,所以会s4引用指向该对象,也就是指向s3的引用了,所以s3和s4引用是一样的,所以s3 == s4是true。
再看一段代码:
1 | String s = new String("1"); |
打印结果是:
- JDK6
falsefalse - JDK7
falsefalse
JDK6中解释是和上面一样的,在JDK7中解释有点不一样,如图:
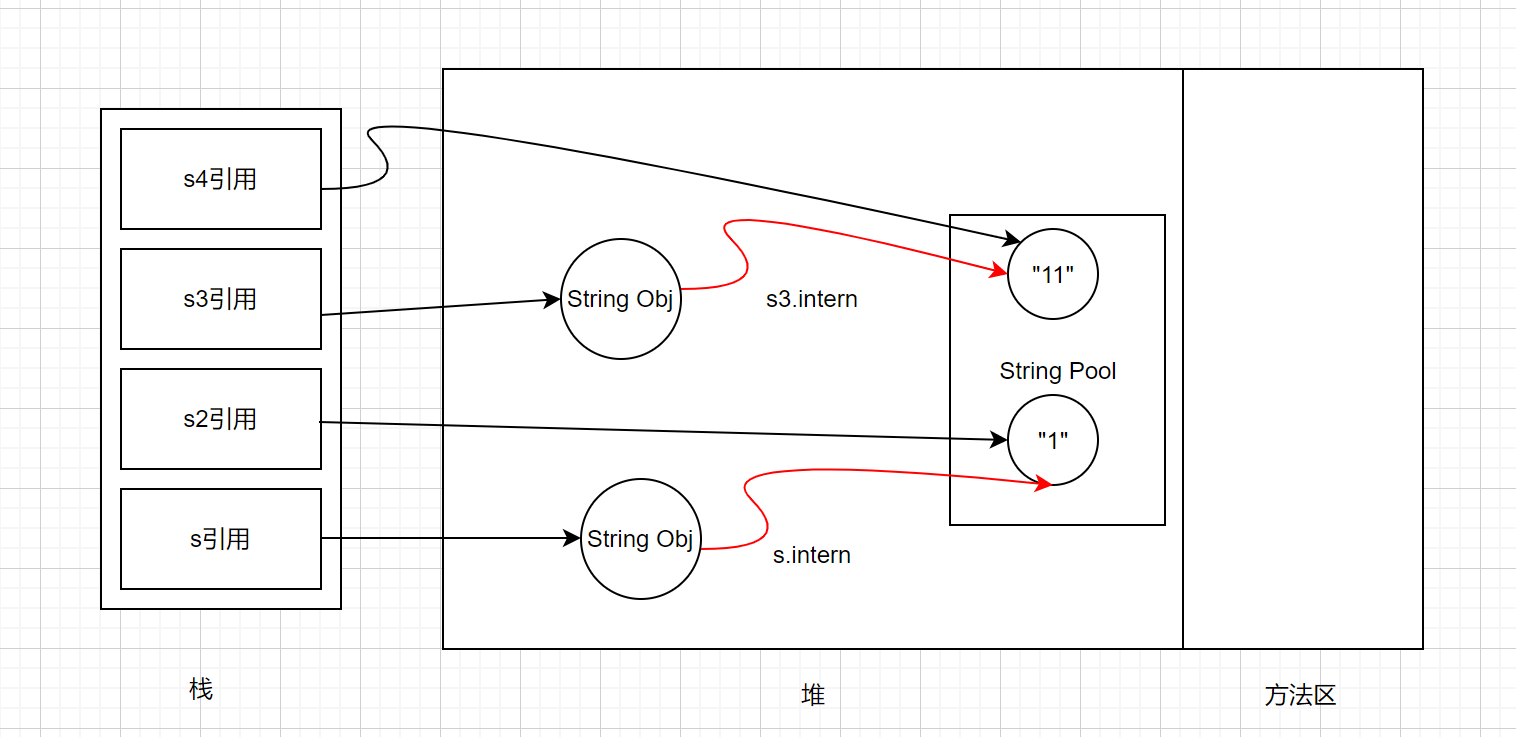
- 在代码s和s1中,s引用对象是指向堆中,s2引用对象是指向常量池中,
s.intern();这行代码往后执行不会有什么影响,因为”1”在常量池中已经存在了,所以s和s1的引用对象是不同的。 - 再看s3和s4,区别就是
s3.intern();往后执行,首先先执行String s4 = "11";常量池不存在”11”,所以生成”11”对象,s4引用并指向该对象,然后s3.intern();此时”11”在常量池中已经存在了,所以没有什么影响,s3引用对象在堆中,s4引用对象在常量池中,所以引用对象是不同的,所以s3 == s4是false。
从上述的例子代码可以看出 jdk7 版本对 intern 操作和常量池都做了一定的修改。主要包括2点:
- 将String常量池从Perm区移动到了Java Heap区
String.intern方法时,如果存在堆中的对象,会直接保存对象的引用,而不会重新创建对象。
五 常用API
| 方法 | 描述 |
|---|---|
str.concat() |
字符串连接,替换+号 |
str.lengt() |
获取字符串长度 |
isEmpty() |
判断字符串是否为空 |
str.charAt(0) |
获取指定位置元素 |
str.codePointAt(0) |
获取指定位置元素,并返回ASCII码值 |
str.getBytes() |
获取byte[] |
str.equals("abc") |
字符串内容比较 |
str.equalsIgnoreCase("abc") |
忽略大小写内容比较 |
str.startsWith("abc") |
开始位置值判断 |
str.endsWith("abc") |
结束位置值判断 |
str.indexOf("abc") |
判断元素开始位置 |
str.lastIndexOf("abc") |
判断元素结束位置 |
str.substring(0 ,1) |
字符串截取 |
str.split(",") |
字符串拆分,支持正则 |
str.replace("a","b")str.replaceAll |
字符串替换 |
str.toUpperCase() |
转大写 |
str.toLowerCase() |
转小写 |
str.toCharArray() |
转char[] |
String.format(str, "") |
格式化 |
str.valueOf("123") |
转字符串 |
str.trim() |
首位去空格 |
str.hashCode() |
获取hashcode值 |
 wechat
wechat alipay
alipay




